Parallelization schemes in Model Parallelism is problematic as sequential layers being parallelized across different accelerators leads to dependencies in the forward and backward passes. This naïve model parallel strategy leads to low utilization of resources as you use only one accelerator at each level, and the parallel efficiency is 1/P. One solution is to have a pipeline or bubble-based parallelism like GPipe [3]. Another approach is to have domain parallelism, which is mixed model/data parallelism [4]. We see that most approaches in use today require data parallelism, and one of the best ways to scale data parallel approaches is by parallelizing the data, i.e. increasing the batch size.
Another challenge is that there is no general optimizer that works well on different problem domains. Some optimizers tend to work well for certain problems but fail on others. Stochastic Gradient Descent (SGD) and Momentum work well on ImageNet, where adaptive optimizers like Adam and AdaGrad fail. Meanwhile Adam and AdaGrad work in the Natural Language Processing (NLP) tasks, while SGD and Momentum fail.
Why is Scaling of Deep Learning Difficult?
-
Generalization Problem: Since large batch training is a sharp minimization problem, this leads to having a high train accuracy, but a low test accuracy [on large-batch training for deep learning].
-
Optimization difficulty: It is hard to get the right hyper-parameters even with auto tuner when we keep increasing the batch size. Training models with large batch size require lots of optimization techniques compared to model with smaller batch sizes to achieve the same accuracy [5].
Goyal et. al. were able to train ImageNet and maintain a good accuracy up to a batch size of 8k, but the optimization was difficult [5]. They had to auto-tune the hyper-parameters and use techniques such as the linear-scaling rule [6], warmup rule [5] to avoid divergence in the beginning, reducing the variance [on the variance of adaptive learning rate and beyond], and data augmentation. However, these techniques are not transferrable to other problems, and Facebook’s recipe does not work for AlexNet, where they were only able to scale to a batch size of 1024.
Observation: Different Gradient-Weight Ratios
When training a network with multiple layers, it was observed that the ratio of the L2 norm of weights (W) and gradients (G) varies significantly between i) weights and biases ii) between different layers. This ratio is high initially and decreases in the first few epochs.
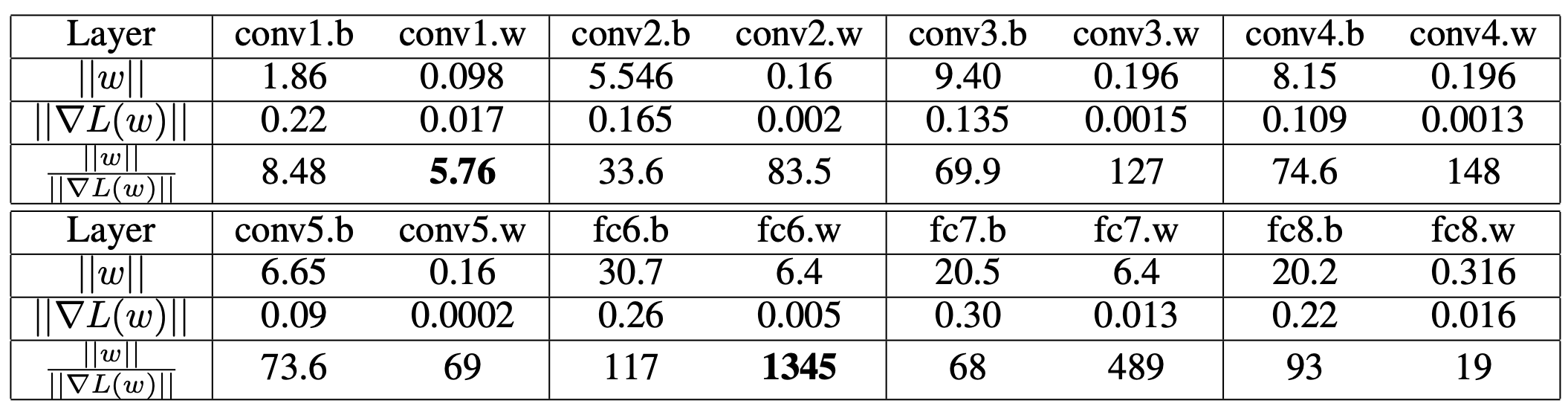
This ratio is termed the “trust ratio” (Rt) and can be interpreted as an approximation of the inverse of the Lipschitz constant of the gradient, and how much we “trust” a layer to change its weights during a single update. Another observation was that a learning rate optimal for the final layer, makes the first layer diverge.
LARS - Layer-wise Adaptive Rate Scaling
This key observation led You, et. al. to propose Layer-wise Adaptive Rate Scaling (LARS) - using local adaptive learning rates for each layer, where the learning rate (η) is updated using the “trust coefficient”. Allowing for weight decay, we get this expression for learning rate:
\[\eta = \eta(global) * {||W^l_t|| \over ||G^l_t|| + \beta||W^l_t||}\]Each layer has a unique learning rate, and the trust ratio changes during every iteration allowing for adaptive scaling at runtime. Whereas Facebook’s approach was able to scale AlexNet to a batch size of 1024, LARS was able to push the batch size up to 8k, without any performance degradation. LARS was also able to scale ImageNet to a batch size of 32k, with warmup, where previous approaches could scale only up to 8k. Compared to the state of the art (goyal et. al.), LARS has a constant top 1% error rate on ImageNet with batch sizes of up to 32k.
LAMB - Layer-wise Adaptive Moments optimizer for Batch training
Using LARS, ResNet-50 can be trained in a few minutes. However, this performance of LARS is not consistent across training for different tasks, such as NLP tasks like BERT or SQuAD. To tackle this problem, Layer-Wise Adaptive Moments optimizer for Batch training (LAMB) was designed, which modifies LARS in the following ways -
-
The trust ratio is allowed to have a maximum value of 10.
-
It uses Adams weighted update rule, instead of Stochastic Gradient Descent.
-
The denominator of the trust coefficient trust ratio is slightly modified to be \(||G^l_t|| + \beta||W^l_t||\).
These changes allow LAMB to have adaptive element wise weight decay, and layer wise correction/normalization. This allows LAMB to perform better than LARS. Whereas LARS diverges at a batch size of 16k on BERT, LAMB is able to scale to 32k while having a better F1 score compared to LARS. LAMB also works for ImageNet/ResNet-50 raining, where it beat out other optimizers [goyal et al], and LAMB has helped Google achieve state of the art results on GLUE, RACE and SQuAD benchmarks.
References
- You, Yang, et al. “Large Batch Training of Convolutional Networks.” ArXiv:1708.03888 [Cs], Sept. 2017. arXiv.org, link.
- You, Yang, et al. “Large Batch Optimization for Deep Learning: Training BERT in 76 Minutes.” ArXiv:1904.00962 [Cs, Stat], Jan. 2020. arXiv.org, link.
- Huang, Yanping, et al. “GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism.” ArXiv:1811.06965 [Cs], July 2019. arXiv.org, link.
- Shazeer, Noam, et al. “Mesh-TensorFlow: Deep Learning for Supercomputers.” ArXiv:1811.02084 [Cs, Stat], Nov. 2018. arXiv.org, link.
- Goyal, Priya, et al. “Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour.” ArXiv:1706.02677 [Cs], Apr. 2018. arXiv.org, link.
- Krizhevsky, Alex. “One Weird Trick for Parallelizing Convolutional Neural Networks.” ArXiv:1404.5997 [Cs], Apr. 2014. arXiv.org, link.
- Ghadimi, Saeed, and Guanghui Lan. “Accelerated Gradient Methods for Nonconvex Nonlinear and Stochastic Programming.” ArXiv:1310.3787 [Math], Oct. 2013. arXiv.org, link.
{kind=link}